




热搜关键词: PCIe高速数据采集卡RFSOC高速数据采集软件无线电平台VPX高速数据采集卡高速信号采集卡PCIe数据采集数字信号处理

✕

一、概述

具备多次触发的连续数据流模式
可长时间进行雷达信号仿真和模拟
高SNR(>90dB)与SFDR(>105dB)
高SNR(>90dB)与SFDR(>105dB)
|
PCIe
|
是新的总线和接口标准,PCIe属于高速串行点对点双通道高带宽传输,所连接的设备分配独享通道带宽,不共享总线带宽,主要支持主动电源管理,错误报告,端对端的可靠性传输,热插拔以及服务质量(QOS)等功能。PCIe交由PCI-SIG(PCI特殊兴趣组织)认证发布后才改名为“PCI-Express”,简称“PCI-E”。 |
|
DMA
|
(Direct Memory Access,直接内存存取) 是所有现代电脑的重要特色,它允许不同速度的硬件装置来沟通,而不需要依于 CPU 的大量中断负载。 |
|
ADC
|
模拟到数字式转换器 |
|
CreateFile
|
是一个多功能的函数,可打开或创建以下对象,并返回可访问的句柄:控制台,通信资源,目录(只读打开),磁盘驱动器,文件,邮槽,管道。
|
|
ReadFile
|
从文件指针指向的位置开始将数据读出到一个文件中,且支持同步和异步操作如果文件打开方式没有指明FILE_FLAG_OVERLAPPED的话,当程序调用成功时,它将实际读出文件的字节数保存到lpNumberOfBytesRead指明的地址空间中。 |
|
WriteFile
|
WriteFile函数将数据写入一个文件。该函数比fwrite函数要灵活的多。也可将这个函数应用于对通信设备、管道、套接字以及邮槽的处理 |
|
fwrite
|
fwrite是C语言函数,指向文件写入一个数据块。 |
|
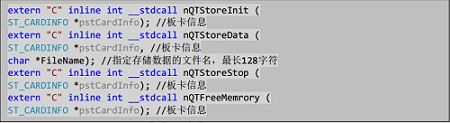
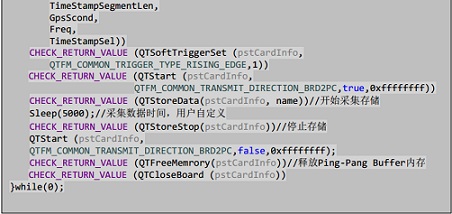
nQTStoreInit
|
输入参数为板卡信息块,通过调用此接口申请好 Ping-Pang buffer。
|
|
nQTStoreData
|
根据用户指定的文件名创建好文件,并且开始采集存储。
|
|
nQTStoreStop
|
停止采集和存储。 |
|
nQTFreeMemory
|
释放 Ping-Pang buffer 的内存。 |
微星X99A SLI PLUS主板
Intel i7-5820k 处理器
金士顿 8GB DDR4 内存x4

Spectrum M2i.4912:8通道,16bit,10MS/s采样率AD采集卡
±200mV到±10V软件可调增益设置
PCIe2.0 x1接口

NVIDIA GeForce GTX 980
支持CUDA 并行处理
4TB RAID0磁盘阵列
磁盘阵列由4块1TB三星固态硬盘组成,每个固态硬盘支持大500MS/s(实测)的写入速度,组成RAID0阵列后支持大1.2GB/s(实测)的写入速度。RAID0磁盘没有奇偶数目的要求,数据被平均分割存储到多个磁盘上,总的读写速度就是磁盘数量乘以单个磁盘的读写速度,缺点在于一块磁盘损坏,则整个磁盘阵列即坏,数据无法被修复。
Control Center:Control center是spectrum公司的专有的控制采集卡校准、license激活、底层kernel控制的软件。启动control center有Kernel Register Settings,可以设置底层kernel开辟的物理连续地址空间,用于DMA大数据量存储使用。
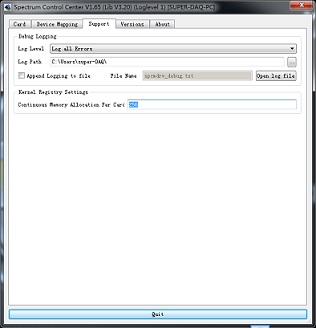
当使用虚拟的内存来进行DMA传输数据的时候,这个过程是非常复杂的。
因为,DMA传输数据是直接通过物理地址传递的,这样DMA传输就得通过每个独立的4kByte的页来进行传输,这样每次DMA传输的数据都是在不同物理地址4kByte页上切换到降低DMA传输的效率。
Spectrum kernel driver:Spectrum公司通过自己底层驱动,可以通过软件向底层申请开辟一段物理地址连续的地址空间,申请完,需要重启电脑,重启电脑,在PC机boot的过程中,需要多花费平时的80%的启动时间。
恰好达到PCIe接口的极限速度。采集到的信号在写入磁盘时总的数据量为:
限制文件存储速度的终瓶颈还是磁盘的固有特性,我们所能做到只是改善软件的实现去逼近硬盘的极限读写速度。一般windows系统粘贴拷贝文件的时候,影响存储速度地方就在于它利用了windows文件缓存机制,当你拷贝一个大文件时,windows会根据你要拷贝的文件大小缓存很大一部分到系统缓存,这时候你会看到系统缓存瞬间飙涨,机器性能大大降低,所以我们要避免使用windows缓存机制,并且尽量读写连续的文件块。
一般来说,我们操作一个windows I/O句柄用的是windows文件读写系列API:CreateFile, ReadFile, WriteFile等,这些API不仅可以读写文件句柄,所有的I/O设备句柄都能通过这些API来操作。比如socket描述符, 串口描述符,管道描述符等。通过设置他们的参数,我们可以选择以不同的方式操作IO。
1. 文件的存取开头的字节偏移量必须是扇区尺寸的整倍数。
2. 文件存取的字节数必须是扇区尺寸的整倍数。例如,如果扇区尺寸是512字节。程序就可以读或者写512,1024或者2048字节,但不能够是335,981或者7171字节。
3. 进行读和写操作的地址必须在扇区的对齐位置,在内存中对齐的地址是扇区。尺寸的整倍数。一个将缓冲区与扇区尺寸对齐的途径是使用VirtualAlloc函数。
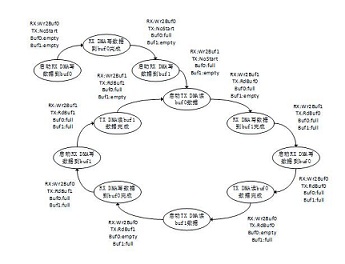
Buf0和Buf1收发数据为ping-pang原理,Buf0和Buf1的状态为empty和full,当数据通过TX DMA读出后,Buf的状态置为empty,当数据通过RX DMA写入后,Buf的状态置为full。RX DMA和TX DMA的状态分别有WrBuf0,WrBuf1,RdBuf0,RdBuf1,OpCmpt,NotStart,TXHungry0,TXHungry1几种状态。
对于ADC接收数据方向,RX DMA写buf0产生完成中断后,首先开始写buf1操作,然后建立写buf0的DMA接收链表。同样当RX DMA写buf1产生完成中断后,首先开始写buf0操作,然后建立写buf1的DMA接收链表。
![]()
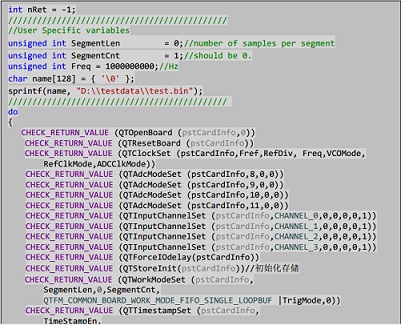
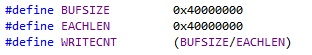
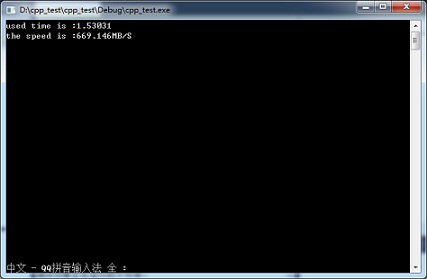
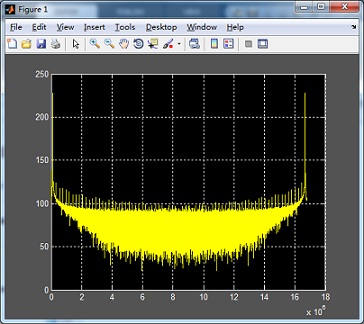
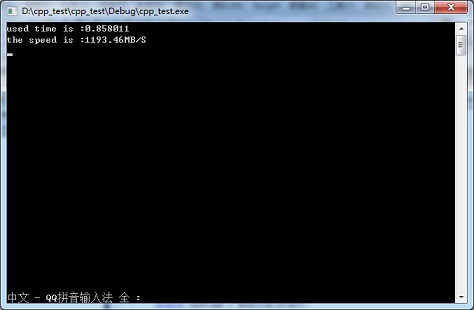
下图为写入1GB数据时使用WriteFile进行写数据操作时实测的速度:
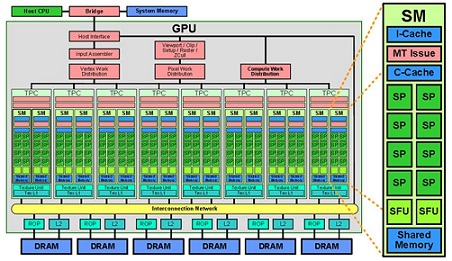
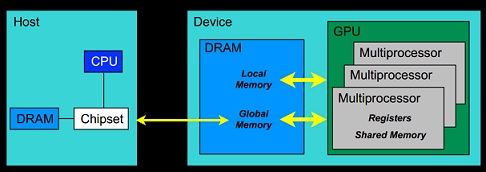
cudaMalloc(): 与C语言中的malloc函数一样,用户函数分配线性内存空间。
cudaMemcpy():与C语言中的memcpy函数一样,只是此函数可以在主机内存和GPU内存之间互相拷贝数据。
cudaFree(): 与C语言中的free函数一样,只是此函数释放的是
cudaMalloc: 分配的内存,主要用于释放线性内存空间。
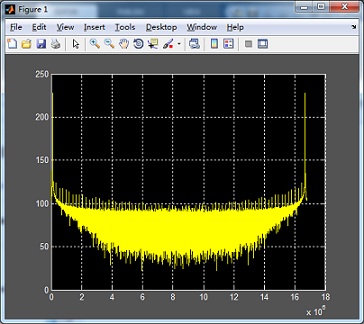
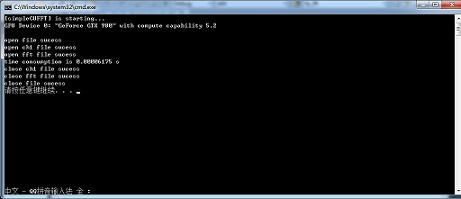
对GPU FFT运算之后的结果,10M个实部real和10M个虚部imag,用MATLAB进行仿真,如下图: